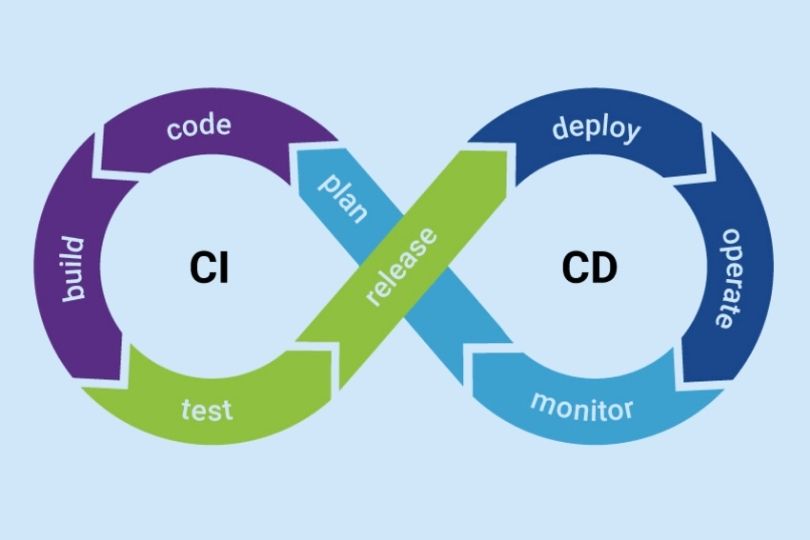
SRE Welcome to DreamsPlus – Master Site Reliability Engineering (SRE) with Our Expert-Led Certification Course